اگر آپ آئی ٹی پروفیشنل ہیں، تو آپ جانتے ہیں کہ OCR کا مطلب آپٹیکل کریکٹر ریکگنیشن ہے۔ اور آپ یہ بھی جانتے ہیں کہ Adobe OCR متن کو نہیں پہچانتا۔ لیکن جو آپ نہیں جانتے ہو وہ یہ ہے کہ اس مسئلے کو کیسے حل کیا جائے۔ متن کو پہچاننے کے لیے آپ Adobe OCR حاصل کرنے کی کوشش کر سکتے ہیں۔ پہلی چیز جس کی آپ کوشش کر سکتے ہیں وہ ہے اپنے Adobe Acrobat سافٹ ویئر کو اپ ڈیٹ کرنا۔ کبھی کبھی، صرف اپنے سافٹ ویئر کو اپ ڈیٹ کرنے سے مسئلہ حل ہو سکتا ہے۔ اگر آپ کے سافٹ ویئر کو اپ ڈیٹ کرنا کام نہیں کرتا ہے، تو اگلی چیز جس کی آپ کوشش کر سکتے ہیں وہ ہے شناخت کی زبان کو تبدیل کرنا۔ ایسا کرنے کے لیے، Adobe Acrobat کھولیں، 'Edit' اور پھر 'Preferences' پر کلک کریں۔ وہاں سے، 'Language' اور پھر 'Recognition' پر کلک کریں۔ آخر میں، وہ زبان منتخب کریں جسے آپ شناخت کے لیے استعمال کرنا چاہتے ہیں۔ اگر شناختی زبان کو تبدیل کرنا کام نہیں کرتا ہے، تو اگلی چیز جس کی آپ کوشش کر سکتے ہیں وہ ہے OCR کی ترتیبات کو تبدیل کرنا۔ ایسا کرنے کے لیے، Adobe Acrobat کھولیں، 'Edit' اور پھر 'Preferences' پر کلک کریں۔ وہاں سے، 'OCR' اور پھر 'Settings' پر کلک کریں۔ آخر میں، یہ دیکھنے کے لیے ترتیبات کو تبدیل کریں کہ آیا اس سے مسئلہ حل ہوتا ہے۔ اگر آپ نے ان تمام چیزوں کو آزما لیا ہے اور Adobe OCR پھر بھی متن کو نہیں پہچانتا ہے تو مسئلہ آپ کی PDF فائل میں ہو سکتا ہے۔ اگر ایسا ہے تو، آپ کو مدد کے لیے ایڈوب کسٹمر سپورٹ سے رابطہ کرنا ہوگا۔
آپٹیکل کریکٹر ریکگنیشن (OCR) ان لوگوں کے لیے کٹی ہوئی روٹی سے بہتر ہو سکتا ہے جنہیں متن کے صفحات کو قابل تدوین متن میں تبدیل کرنے کی ضرورت ہے۔ ہوسکتا ہے کہ آپ کے پاس متن کے صفحات ہوں جنہیں آپ اپنے کمپیوٹر پر اسکین کر رہے ہیں جنہیں اب قابل تدوین شکل میں تبدیل کرنے کی ضرورت ہے۔ شاید ٹائپ کرنے کے لیے کافی وقت نہیں ہے، یا ٹائپ کرنے کے لیے بہت زیادہ وقت ہے۔ ٹھیک ہے، آپٹیکل کریکٹر ریکگنیشن صرف اس میں مدد کر سکتی ہے۔ آپ اپنے کمپیوٹر پر صفحات کو اسکین کر سکتے ہیں اور ان کے ساتھ کھول سکتے ہیں۔ ایڈوب ایکروبیٹ اور متن کو پہچاننے اور آپ کو قابل تدوین ورژن دینے کے لیے OCR فنکشن استعمال کرنے کی کوشش کریں۔ جیسے ہی آپ فتح کا رقص کرنے والے ہیں، آپ کو ایک غلطی کا پیغام ملے گا۔ ایکروبیٹ اس صفحہ پر OCR انجام دینے سے قاصر تھا کیونکہ اس صفحہ میں ڈسپلے ٹیکسٹ ہے۔
ونڈوز 7 بوٹ مینو میں ترمیم کریں
Adobe OCR متن کو نہیں پہچانتا ہے۔

Acrobat Professional میں OCR صلاحیتیں ہیں جو آپ کو اسکین شدہ دستاویزات کو RTF یا Microsoft Word دستاویزات کے طور پر، Doc اور Docx دونوں کو محفوظ کرنے کی اجازت دیتی ہیں۔ ایسے وقت ہوسکتے ہیں جب آپ Adobe Acrobat Professional میں کوئی دستاویز کھولتے ہیں اور کچھ متن دیکھتے ہیں، لیکن Acrobat ایک غلطی پھینک دیتا ہے۔ ایکروبیٹ OCR استعمال نہیں کر سکتا۔ یہ کئی وجوہات کی وجہ سے ہو سکتا ہے۔
- پیش کردہ/ قابل تدوین متن
- مسخ شدہ یا دھندلا ذریعہ
- ناقص اصل
- گرافکس اور فارم
ایکروبیٹ اس صفحہ پر OCR انجام دینے سے قاصر تھا کیونکہ اس صفحہ میں ڈسپلے ٹیکسٹ ہے۔
1] پیش کردہ/ قابل تدوین متن
چلانے کے قابل متن قابل تدوین متن ہے جو فائل میں موجود ہے جس کے لیے آپ کردار کی شناخت کرنا چاہتے ہیں۔ ایکروبیٹ کسی دستاویز پر OCR انجام نہیں دے سکتا جس میں ڈسپلے ٹیکسٹ ہو۔ OCR اسکین کی خرابی کی یہ سب سے کم واضح وجہ ہے کیونکہ ہم ہمیشہ یہ فرض کرتے ہیں کہ پڑھا جانے والا متن بھی OCR کے ذریعے اسکین کیا جانا چاہیے۔
جواب:
اگر غلطی ہو تو اس سے نمٹنے کے دو طریقے ہیں۔
- کسی دستاویز کی کاپی حاصل کرنے کی کوشش کریں جس میں کوئی ڈسپلے ٹیکسٹ نہ ہو۔
- پی ڈی ایف کو TIFF میں تبدیل کریں، پھر پی ڈی ایف میں واپس جائیں اور دوبارہ OCR کی کوشش کریں۔
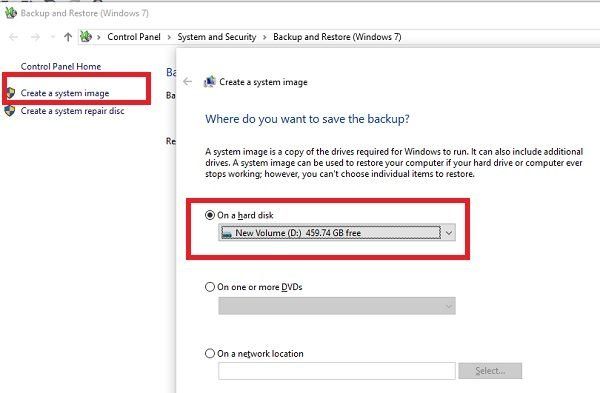
پی ڈی ایف کو TIFF میں تبدیل کرنے کے لیے، اسے ایکروبیٹ میں کھولیں اور فائل کا انتخاب کریں، پھر اس کو محفوظ کریں۔ جب Save As ڈائیلاگ باکس ظاہر ہوتا ہے، تو فائل ٹائپ کی فہرست سے TIFF (*.tif، *.tiff) کو منتخب کریں۔ اس جگہ کی وضاحت کریں جہاں آپ فائل کو محفوظ کرنا چاہتے ہیں، پھر محفوظ کریں پر کلک کریں۔ ایکروبیٹ پی ڈی ایف دستاویز کے ہر صفحے کو ایک علیحدہ، ترتیب وار نمبر والی TIFF فائل کے طور پر محفوظ کرتا ہے۔ پھر آپ TIFF فائلوں میں سے ہر ایک کو کھولیں اور انہیں پہچاننے کے لیے ایکروبیٹ کا استعمال کریں۔
اگر آپ دستاویزات کو ایک میں ضم کرنا چاہتے ہیں تو درج ذیل کریں:
- ایکروبیٹ کھولیں، منتخب کریں۔ فائل پھر پی ڈی ایف بنائیں پھر متعدد فائلوں سے .
- منتخب کریں۔ براؤز کریں۔ ہر پی ڈی ایف فائل کو منتخب کرنے اور شامل کرنے کے لیے۔ فائلوں کو اس طرح ترتیب دیں جس طرح آپ چاہتے ہیں کہ وہ نئی پی ڈی ایف میں ظاہر ہوں۔
- منتخب کریں۔ ٹھیک .
2] مسخ شدہ یا دھندلا ذریعہ
دھندلی دستاویز
Acrobat کسی دستاویز پر OCR انجام نہ دینے کی ایک اور وجہ یہ ہے کہ اس کی ریزولوشن کم ہے۔ کم ریزولوشن دستاویزات دھندلی ہو سکتی ہیں اور ایکروبیٹ ان پر کردار کی شناخت نہیں کر سکتا۔
جواب:
ہائی ریزولیوشن دستاویز کا ماخذ حاصل کریں۔ اگر آپ کاغذی دستاویز کو اسکین کر رہے ہیں، تو اسکینر کی ریزولوشن کو ایڈجسٹ کریں تاکہ یہ زیادہ ریزولوشن پر اسکین کرے۔
مسخ شدہ دستاویز
ایکروبیٹ کسی دستاویز میں متن کو پہچاننے میں ناکام ہو سکتا ہے جو مناسب طریقے سے منسلک نہیں ہے۔ ہو سکتا ہے دستاویز کو صحیح طریقے سے سکین نہ کیا گیا ہو اس لیے ایکروبیٹ اس پر کردار کی شناخت نہیں کر سکتا۔
جواب:
اسکیننگ شروع کرنے سے پہلے، یقینی بنائیں کہ آپ جس کاغذ پر اسکین کر رہے ہیں وہ فلیٹ ہے۔ آپ فوٹوشاپ میں مسخ شدہ دستاویز کو کھول کر سیدھا بھی کر سکتے ہیں۔ یہاں ایک پوسٹ ہے جو آپ کو دکھائے گی کہ فوٹوشاپ میں سیدھے ٹول کو کیسے استعمال کیا جائے۔ یہ ٹول آپ کو ایکروبیٹ میں OCR کرنے سے پہلے اپنی اسکین شدہ دستاویز کو سیدھا کرنے میں مدد دے سکتا ہے۔
3] ناقص معیار اصل
اگر ماخذ کا مواد ناقص معیار کا ہے، جیسا کہ فیکس، تو ہو سکتا ہے کہ ایکروبیٹ اسے صحیح طریقے سے نہ پہچان سکے۔ اس کے بعد آپ کو بہتر کوالٹی یا آؤٹ پٹ کو درست کرنے کا خطرہ مول لینا پڑے گا۔
جواب:
win32k.sys کیا ہے؟
OCR کے لیے بہترین معیار کا ذریعہ حاصل کریں۔ اگر آپ کے پاس کم معیار کی دستاویز ہے تو آپ کو OCR چلانا پڑے گا اور امید ہے کہ کم از کم اس میں سے کچھ کو پہچان لیا جائے گا اور پھر گمشدہ حصوں کو پُر کریں۔
4] گرافکس اور شکلیں۔
گرافکس اور شکلوں کو ملانے والی دستاویزات کو ایکروبیٹ میں OCR نہیں کیا جائے گا۔ ایکروبیٹ کے ساتھ OCR کے لیے استعمال کیے جانے والے دستاویزات میں گرافکس یا مخلوط شکلیں نہیں ہونی چاہئیں، ورنہ اس کے نتیجے میں خرابی ہو سکتی ہے یا آؤٹ پٹ غلط ہو سکتا ہے۔
جواب:
OCR انجام دینے کے لیے دستاویز کا متنی ورژن تلاش کریں۔ آپ کو گرافکس اور شکلوں کے ساتھ دستاویز کی شناخت کرنے کی بھی ضرورت ہوسکتی ہے، اگر یہ کام کرتا ہے تو آپ کو آؤٹ پٹ میں تصحیح کرنے کی ضرورت پڑسکتی ہے۔
Adobe Acrobat میں OCR کیا ہے؟
OCR وہ عمل ہے جس کے ذریعے Acrobat pixelated متن یا تصاویر کی توثیق کرتا ہے۔ ہر کردار کو پہچان کر متن میں تبدیل کیا جاتا ہے۔ ایکروبیٹ تصویر کی شکل اور لائن کے وزن کا موازنہ OCR کے دوران آپ کے کمپیوٹر پر پہلے سے نصب فونٹس سے کرتا ہے۔ OCR اسکین کی خرابی کی وجوہات درج ذیل ہیں۔
کون سا فائل فارمیٹ OCR کے لیے موزوں نہیں ہے؟
OCR کے لیے محفوظ کرنے کے لیے JPEG فائل فارمیٹ بہترین نہیں ہے کیونکہ JPEG جب بھی محفوظ ہوتا ہے اس کا معیار کھو جاتا ہے۔ یہاں تک کہ اگر آپ JPEG کو PDF میں تبدیل کر رہے ہیں، تب بھی یہ خراب معیار کا ہو سکتا ہے۔ اگر آپ ان پر کریکٹر ریکگنیشن کرنا چاہتے ہیں تو اپنے دستاویزات کو PDF یا TIFF کے بطور محفوظ کرنا بہتر ہے۔